

Homo Economicus es un tipo muy inteligente que se levanta todos los días, y computa cuanto podría ganar trabajando el resto de su vida laboral activa, computa la utilidad que podría derivar del consumo de todas las combinatorias posibles de bienes (incluyendo el ocio), en los distintos momentos del tiempo y elige un sendero de esfuerzo laboral y consumo intertemporal que le permite alcanzar la máxima utilidad esperada.
Homo Sapiens Sapiens, en cambio, se levanta todos los días y compara la canasta de consumo (incluyendo siempre el ocio) que su microclima cultural (familia, barrio, amigos) le impone como default, con un puñado de canastas alternativas que surgen de pivotear en torno del máximo local que supo alcanzar, cambiando de a no más de 7 productos por vez.
Pero la clave de lo que hoy quiero contarles es que antes de elegir un curso de acción, Homo Sapiens Sapiens necesita representarse mentalmente cada una de esas canastas alternativas.
Quiero aquí traer un par de citas al ruedo para que imaginemos la naturaleza de esas representaciones.
Decía Ernesto Sábato que “El hombre primero siente el mundo y luego cavila sobre el mundo” e iniciaba Lev Vigotsky su obra Pensamiento y Lenguaje con un pasaje de Mandelstam que dice “Olvidó una palabra y su pensamiento incorpóreo ingreso en el reino de las sombras”.
La cita del autor de Héroes y Tumbas tiene que ver con la memoria episódica de los sujetos, cargada e impregnada de lo que Antonio Damasio denominó “marcadores somáticos” y que remiten a las emociones que experimentamos en cada momento de nuestras vidas que recordamos.
La referencia al famoso Psicólogo bielorruso, en cambio, apunta a la memoria semántica de los individuos; almacén donde se guardan los recuerdos aprendidos, pero sin hache.

Ahora bien, el título les prometió que el funcionamiento de la mente y la econometría tenían algo que ver y resulta que como lo demostraron las investigaciones del profesor Antonio Rangel del Instituto Tecnológico de California, el cómputo de las señales neuronales que se activan cuando cada uno de los sistemas de memoria evocan la situación sobre la que debe elegir un sujeto, con el objeto de inferir la utilidad que obtendrá de un curso de acción determinado, se efectúa en la corteza prefrontal ventromedial de nuestro cerebro.
Dado que la memoria de trabajo (de corto plazo) es limitada en lo que respecta tanto a su capacidad de almacenamiento como al tiempo durante el cual los datos pueden ser conservados, los valores de decisión computados no pueden ser comparados todos entre sí, motivo por el cual es habitual que se los contraste con un repertorio preestablecido de opciones, es decir, un escenario de statu quo que funciona como punto de referencia.
En la memoria RAM de las computadoras personales la capacidad de almacenamiento también es limitada (el span de memoria) y la duración de los datos en la misma está supeditada a la disponibilidad de una fuente de energía continua, razón por la cual se pierde la información cuando se apaga la máquina o se corta la corriente.
En la memoria de corto plazo, la energía que mantiene la información disponible (online) es la atención, y la variable que determina a qué porciones de información se les presta atención normalmente está asociada a preferencias estimulares innatas o modularizadas a la manera de Karmiloff Smith.
Es razonable entonces pensar que los marcadores somáticos o las emociones en general funcionan como vectores informativos que dirigen la atención hacia algunos aspectos particulares de las alternativas bajo análisis, por lo cual queda descartada de plano tanto la posibilidad de que el cerebro compute los niveles de utilidad estimada de todos los cursos de acción posibles (por limitaciones de capacidad), así como la posibilidad de que calcule las alternativas correspondientes a todas las dimensiones posibles que presenta cada una de las opciones (por limitaciones atencionales). Si tales posibilidades se concretasen estaríamos en el terreno de la indeterminación computacional (indeterminación de Goodman).
Entonces, una vez que elegimos entre las opciones alternativas y efectuamos el consumo, experimentamos una utilidad que neuroanatómicamente está asociada a la activación de un área denominada corteza frontal orbital, conjuntamente con la activación del núcleo accumbens.
La información producida por la corteza frontal orbital es almacenada en la memoria episódica de largo plazo, que será el lugar en el cual la memoria de trabajo buscará información la próxima vez que tenga que computar las señales neuronales correspondientes al valor de esa alternativa en la corteza prefrontal ventromedial.
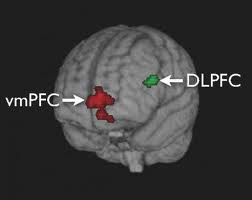
Ahora bien, acá es donde la econometría y la neuroeconomía se dan la mano, porque resulta que el cómputo de las señales que median el proceso de elección de alternativas es, como cualquier fenómeno neuronal, de naturaleza estocástica (contiene una cuota de azar); esto quiere decir que el cálculo de la utilidad que a la postre proporcionarán las opciones elegidas, es en última instancia un problema de inferencia estadística, de modo que el margen de error resultante (incluso suponiendo que no exista sesgo) dependerá del tamaño de la muestra a partir de la cual el individuo realiza la inferencia (su experiencia) y sobre todo de la varianza de esas experiencias.
Obviamente cuando se trate de elecciones repetitivas y relativamente triviales, sobre las cuales tenemos mucha experiencia (por ejemplo, elegir la bebida del almuerzo, o la hamburguesa de McDonald’s), es plausible pensar que la varianza en el error será lo suficientemente acotada como para que no exista mucha diferencia entre el resultado de nuestras elecciones y lo que podría predecir la teoría neoclásica de la preferencia revelada.
Pero medida que las elecciones se adentren en el terreno de las alternativas no conocidas ni experimentadas, los márgenes de error serán mayores, y cuando entre las variables a considerar se incluyan alternativas o contextos desconocidos, el sistema ya no podrá utilizar información generada por la corteza frontal orbital y el núcleo accumbens (almacenada en la memoria episódica de manera directa), sino que deberá producir estimaciones de la utilidad esperada a partir de la experiencia registrada en situaciones evaluadas como lo más similares posibles a la nueva situación.
Claramente, el modelo de generación de similitudes, o de matching de escenarios, será construido de manera diferente por cada persona, e influirá significativamente la capacidad cognitiva de cada individuo tanto para administrar la información en la memoria de trabajo como para procesarla. Puesto en términos econométricos, no todos venimos dotados de la misma versión de STATA, ni todos tenemos la misma capacidad computacional para correr los modelos.
El problema de fondo entonces, es que epistemológicamente necesitamos una teoría que, partiendo del análisis de los datos que forman y afectan nuestro medio ambiente o nuestra realidad (en el sentido amplio de la palabra), pueda explicar el modo en que formulamos o estimamos el proceso generador de esos datos: nuestro modelo del funcionamiento del mundo.
Ahora bien, si consideramos la naturaleza de los datos, la diversidad de las experiencias a partir de las cuales generamos nuestro modelo del funcionamiento del mundo es muy amplia.
Algunos datos de nuestra realidad presentan una estructura que en estadística se denomina cross section y que, en palabras más simples, refiere a datos distintos que observamos en un solo momento del tiempo, los cuales nos brindan la posibilidad de realizar una primera clasificación. Por ejemplo, podemos dividir nuestro mundo en hombres y mujeres, viejos y jóvenes, ricos y pobres, gordos y flacos, lindos y feos, etcétera.
Luego, esas generalizaciones nos permiten establecer relaciones y efectuar inferencias, como cuando notamos que las mujeres lindas y jóvenes pocas veces salen con hombres viejos, feos y gordos, salvo que ellos sean, además, ricos.
Esa estructura simple de datos distintos a partir de los cuales aprendemos y generalizamos nos conduce a elaborar un modelo del funcionamiento del mundo que no es determinístico sino probabilístico, en el sentido de que no podemos trazar correspondencias simples, lineales o unívocas entre los datos, sino en todo caso efectuar estimaciones con un mayor o menor margen de error.
Por ejemplo, al observar a personas jóvenes y a individuos mayores en un momento dado, cualquiera nota que la edad afecta el bienestar físico. De allí resultará casi natural presuponer que una persona de la tercera edad corre más despacio o tiene menos resistencia física que un joven de 25 años, pero la estimación que pueda hacerse del rendimiento según la edad naturalmente tendrá un margen de error, pues muchos conocemos alguna persona de 70 años de edad que corre maratones y estamos familiarizados con jóvenes de 30 que no pueden subir dos pisos por escalera sin agitarse.
La segunda estructura de datos más habitual a partir de la cual aprendemos cómo funciona la realidad que nos rodea es la que en estadística se denomina series de tiempo, que tiene que ver con las generalizaciones que podemos realizar a partir de las relaciones que existen entre los objetos, pero no en un momento dado sino a lo largo del tiempo. Por ejemplo, quien estudia más horas y con mayor constancia se recibe antes y con mejores notas; el que hace deportes todos los días se enferma menos y luce mejor la ropa de verano; el que fuma y abusa del alcohol tiene menor expectativa de vida; el que aprende a manejar la ansiedad tiene más éxito en sus relaciones amorosas.
Es decir, es posible observar una relación de causalidad entre una conducta y un resultado, pero esa relación no se percibe de manera instantánea, sino que se evidencia con el paso del tiempo. Al igual que en el caso anterior, la causalidad es probabilística, y las explicaciones que construimos a partir de nuestras experiencias son generalizaciones que a la fuerza poseen un margen de error.
Finalmente, existe una última estructura de datos que usamos como base para pronosticar las consecuencias de nuestros actos y nuestras conductas de consumo, que en estadística se denomina datos de panel. Refiere a las observaciones que permiten detectar relaciones e inferir correlatos combinando simultáneamente datos provenientes de fuentes diversas que observamos en un momento dado (cross section) con información resultante de la evolución de las variables a lo largo del tiempo (series de tiempo).
Esta última estructura es la más habitual en la realidad. Por ejemplo, cuando observamos la trayectoria universitaria de un grupo de amigos o conocidos, sabemos en cada momento particular quién aprueba tal o cual examen y quién no, pero también conocemos la historia de cada sujeto en materia académica, la cual se desarrolla a lo largo del tiempo.
Así, mi hipótesis es que en general lo que hacen las redes neuronales de nuestro cerebro es más o menos lo mismo que hacen los programas estadísticos más famosos (como el SPSS, el STATA o el ESTADÍSTICA): procesan la información proveniente de nuestras experiencias (y de las experiencias de los demás, que conocemos a partir de relatos escuchados, leídos o vistos en la televisión, el cine, la oficina y el club), y elaboran como resultado un modelo que explica la relación que existe entre las variables; se trata de una simplificación de la realidad a partir de la cual estimamos las consecuencias de nuestros actos y decisiones.
Por esta razón, una persona de 18 años de edad y otra de 50 no realizan las mismas elecciones. Asimismo, una persona familiarizada con el contexto del problema que enfrenta procesa la información de una forma, y alguien que desconoce las reglas del ámbito novedoso en que debe desenvolverse procesa los datos en forma diferente.
Por ejemplo, analicemos el caso de quien elige una carrera universitaria. Supongamos que Juan y Pedro tienen exactamente las mismas preferencias respecto del tipo de vida que desean tener. Si el modelo mental que Juan ha construido y que relaciona “carrera x” con “estilo de vida x” y “carrera y” con “estilo de vida y” es erróneo y el modelo de Pedro es correcto, es posible que Juan y Pedro decidan, paradójicamente, elegir carreras distintas.
Otro ejemplo: Andrea y Natalia poseen gustos culinarios similares. Ellas no se conocen y están, cada una en su casa, tratando de elegir el mejor lugar para ir a cenar esta noche. Andrea suele salir a menudo, por lo que está muy familiarizada con la calidad de la comida, el ambiente y el servicio de los distintos restaurantes. Natalia, por el contrario, sale solo de vez en cuando, generalmente en circunstancias especiales que presentan un alto valor emotivo (como el festejo de un cumpleaños o de un aniversario), aunque hoy sus motivaciones para salir a cenar son idénticas a las de Andrea.
Es evidente que los modelos que cada una de estas mujeres construirá respecto del nivel de satisfacción o placer que podrá obtener de la experiencia de ir a cenar a distintos lugares serán completamente diferentes. Andrea efectuará estimaciones muy acertadas de la realidad (no sesgadas y con bajísimo margen de error en términos estadísticos), mientras que Natalia basará su elección en unas pocas experiencias, que además estarán sesgadas por el contenido emocional de sus salidas anteriores, por lo cual probablemente considerará de manera especial algunos atributos que no necesariamente serán relevantes para elegir el mejor lugar para cenar en esta ocasión particular.
Además, al ser pocas sus experiencias previas, el margen de error será enorme y no le resultará fácil decidir. Es altamente probable que estas dos chicas terminen cenando en lugares distintos, aun cuando sus preferencias y objetivos sean similares. Incluso tampoco es implausible pensar que Natalia, al tener una muestra acotada a partir de la cual infiere, termine eligiendo uno u otro lugar con una enorme cuota de aleatoriedad, de modo que no es posible suponer que su elección revela preferencia alguna, siendo incluso factible que las curvas de indiferencia que enfrenta hoy intersecten a las que surjan de sus representaciones mentales de mañana
Más aún. Supongamos que Natalia, por salir poco, tuvo una mala experiencia en el restaurante x (supongamos que el día en que ella fue a comer allí se había roto la heladera del local y la materia prima con la que prepararon la comida no estaba en el mejor estado posible, o que el mozo que la atendió era un joven que estaba nervioso por tratarse de su primer día de trabajo). En ese caso, en las próximas salidas evitará sistemáticamente volver a ese lugar, cometiendo dos de los sesgos típicos descriptos en este libro: el primer sesgo consiste en sacar conclusiones de manera prematura y el segundo tiene que ver con la tendencia de las personas a no registrar cualquier información o evidencia que contradiga sus hipótesis originales.
De ese modo, se producirá lo que en estadística se denomina un sesgo de selección en el modelo mental de Natalia, que la conducirá a estimar incorrectamente el nivel de satisfacción o de utilidad que podría obtener en los distintos lugares.
No solo se equivocará cuando deba computar mentalmente la utilidad estimada de ir al local donde tuvo la mala experiencia, sino también cuando deba calcular la satisfacción que le proporcionará ir a cualquier otro lugar, pues, a diferencia de lo que señalan los teóricos de la preferencia revelada, la neuroeconomía indica que las estimaciones de utilidad que realiza nuestro cerebro tienen carácter relativo o comparativo, y no absoluto (por otro lado, esto es lo que técnicamente haría un modelo estadístico multinomial logit que estimara las probabilidades de elección de un restaurante por el método estadístico de máxima verosimilitud, usando como variable independiente la utilidad experimentada en cada lugar).
Realmente creo que estamos transitando los comienzos de una nueva teoría general de la elección económica, que reemplazará a los consumidores representativos que maximizan funciones de utilidad dadas de antemano por un conjunto heterogéneo de “consumidores prototípicos” que producirán modelos de funcionamiento del mundo a partir de los cuales estimarán el impacto de sus decisiones en funciones objetivo que cambiarán con el contexto de la elección.
Pienso que el nuevo modelo se apoyará en la psicología cognitiva de la memoria y de la inteligencia, en la neuroanatomía, y en la econometría, puesto que la mente, en última instancia es un pequeño STATA.
Martin Tetaz es Economista, egresado de la Universidad Nacional de La Plata, especializado en Economía del Comportamiento, la rama de la disciplina que utiliza los descubrimientos de la Psicología Cognitiva para estudiar nuestras conductas como consumidores e inversores. Actualmente es Diputado Nacional.






